Spring and Groovy are old friends. While you can use POGOs as Spring beans as though they were POJOs, that's not the focus of this article. Instead, I'm going to demonstrate one of the capabilities that is unique (more or less) to Groovy: refreshable beans. They allow you to deploy source code to production that you change while the system is still running. Hey, what could go wrong?
A Silly, But Amusing, Example
Return with me now, boys and girls, to those thrilling days of yesteryear, way back to 2008. It was a simpler time, when:
Pixar’s Wall-E was the number 1 movie in America, and somehow managed to make our future Robot Overlords seem all warm and cuddly.
A new species of stick insect, known as Chan's megastick, was discovered. The specimen donated to London's Natural History Museum measured over 22 inches (!) in length, making it the World's Longest Insect.
(Ew. Maybe it's better if we forget about that one.)
I was going to mention one of the Top Ten Albums of 2008, but I realized I never heard any of them and decided I don't like feeling that old. So never mind.
Yahoo! rejected a take-over bid by Microsoft for $31/share, saying it “substantially undervalued the company”. Yahoo! is currently selling at $36/share. For its part, MSFT is at about $46/share. I don’t know; it seemed like a big deal at the time.
Consider a combined Java / Groovy implementation of a mortgage application that uses Spring. First, I’ll start with the MortgageApplication class itself:
MortgageApplication.groovy,a POGO
import groovy.transform.*
@Canonical
class MortgageApplication {
BigDecimal amount
BigDecimal rate
int years
}
The MortgageApplication class is a Plain Old Groovy Object (POGO). The @Canonical annotation triggers an Abstract Syntax Tree (AST) transformation. The result is a class that has:
Three private attributes (amount, rate, and years)
Public getters and setters for each
A toString method that shows the fully qualified class name, followed by the attributes in order, top down
An override of the equals method that checks the values of all three attributes
An override of the hashCode method consistent with equals
A default constructor
A “map-based” constructor that allows you to set the values of the attributes in any order in any combination
A “tuple” constructor that allows you to supply the attributes in order without labeling them
Not bad for 7 lines of code, including the import statement. There is the minor issue that the mortgage application doesn't include anything about the applicant, but that wouldn't change refreshable bean discussion.
The Spring framework is quite happy to use this POGO as a regular Spring bean. Just declare it in the XML application context file, add a component-based annotation, or use a Java-based config class, and you're good.
When you plan on using Java and Groovy together, one way to minimize integration problems (not that there tend to be many in the first place) is to use Java interfaces. So if the plan is to show a bean with one version in Java and another in Groovy, I might as well use a Java interface that they can both implement.
Here is the Evaluator interface (in Java):
Evaluator.java, an interface implemented by both evaluators
public interface Evaluator {
boolean approve(MortgageApplication application);
}
The bank simply invokes the approve method with an application, and it returns true or false based on whatever business logic they care to implement. Of course, this being early in 2008, we know what they're effectively doing. Here’s the Java implementation.
JavaEvaluator.java
@Component
public class JavaEvaluator implements Evaluator {
public boolean approve(MortgageApplication application) {
return true;
}
}
Not much of a surprise there, given the way things eventually worked out. That also shows why nothing was added to the MortgageApplication class about the person applying?—?it didn’t matter anyway.
The @Component annotation is there so that Spring can find it automatically on a “component scan.” What is a component scan? Funny you should ask. This is a Spring application, so we need some metadata. Like all the cool kids, I’ll use the Java configuration approach. Here's the relevant class:
AppConfig.groovy,a Spring bean configuration file
@Configuration
@ComponentScan
class AppConfig {}
(There’s something truly Zen in the minimalist nature of this class, isn’t there? Truly, we live in magical times.)
The @Configuration annotation indicates that this is a class used to declare beans, rather than being a bean itself. I want it to automatically find all the Spring beans (anything annotated with @Component or one of the annotations based on it) automatically, which is what the @ComponentScan does. It searches the current directory and all of its descendants and finds all the components.
To show the evaluator in action, I'll create a simple Java class that fires up the Spring container and acquires the bean.
Here's my JavaDemo class to do that:
JavaDemo.java
public class JavaDemo {
public static void main(String[] args) {
ApplicationContext ctx =
new AnnotationConfigApplicationContext(AppConfig.class); // 1
Evaluator evaluator = ctx.getBean("javaEvaluator", Evaluator.class); // 2
boolean result = evaluator.approve(null); // 3
System.out.println((result ? "approved" : "denied"));
}
}
? Start up the Spring container
? Get the Java evaluator bean
? Use the bean to approve a mortgage application
In the main method, the AnnotationConfigApplicationContext class is used to read the AppConfig configuration metadata and instantiate the bean. The getBean method retrieves the bean whose id is javaEvaluator (the default name of a bean is the class name with a lowercase first letter) and casts it to the proper type. The evaluator is used to approve a null mortgage application, because why not?
So far, this is all standard Spring, except for the fact that I've been mixing in Groovy implementation files. Spring doesn't care where the byte codes come from, as long as it can resolve all the dependencies.
That reminds me: how do I tell Spring about the dependencies? I use a Gradle build, of course. Here's the build file:
The build tells Gradle to use the JCenter bintray repository to resolve all the dependencies, download them, and cache them locally. The “external” properties (designated as “ext” in the build file) are used to assign the current release versions of the Spring framework and the Spock testing framework to project variables, which are then used in the rest of the dependencies.
After building the project, running the JavaDemo application prints out, naturally enough, true.
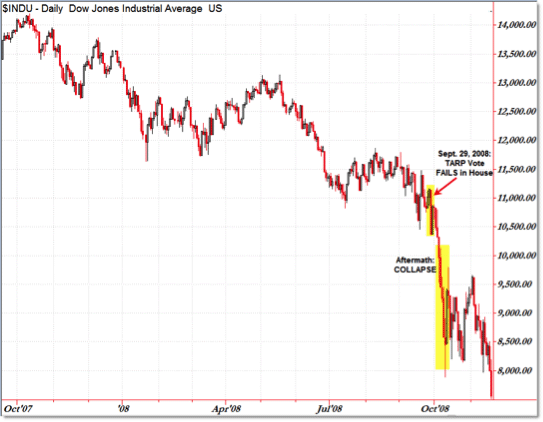
This is all well and good, but what happens when we change our mind? We now move from the Spring (no pun intended) of 2008 to the Fall of the same year. To the considerable astonishment of the banking industry, all of those bad mortgages turned out to be, well, bad. The stock market crashed, LehmanBrothers collapsed, and the entire world financial system teetered on the brink of ruin.
Those were fun days, weren’t they? (Spoiler alert: No. No they were not. Yuck.)
For our part, we have to find some way to stop the bleeding. What we really need to do is to shut down our system and change the implementation of the approve method so that we're not giving away money we don't have.
The problem is, shutting down the system could itself cause a panic. As Mr. Potter (Henry, not Harry) said to George Bailey during a bank run in It’s a Wonderful Life, “George, you close those doors you’ll never open them again!”
Figure 1. The more things change…
Yikes again. If the implementation is in Java, we have no choice. If, on the other hand, we’re willing to use Groovy, we can take actually change our implementation while the system is still running.
A Refreshing Dose of Groovy
Spring is perfectly happy to use compiled Groovy classes anywhere it normally expects to see compiled Java classes, as demonstrated earlier. But for a limited number of dynamic languages, Spring provides an alternative, known as refreshable beans. The idea is that you can deploy actual source code, rather than compiled byte codes, and tell Spring to periodically check to see if the source code has changed. If it has, Spring will detect the change, reload the bean, and add it to the system while it is still in operation.
That’s pretty awesome, but arguably a rather dangerous idea. How would you like the ability to modify running code in production? Hey, what could go wrong?
(The answer is pretty much everything, which is why we watch.)
In this particular case, now I want to add Groovy source code to my system in a way that does not result in compiled code in the classpath. To do this, I need to use the lang namespace.
The Java configuration class approach is great for most things, but adding tags from alternative namespaces isn’t necessarily the easiest thing to do. In this case, it turns out that using XML is actually helpful.
Here is an applicationContext.xml file that declares the lang namespace, and then adds a Groovy evaluator as a refreshable bean.
applicationContext.xml, in the src/main/resources directory
Declaring the lang namespace makes the lang:groovy tag available. This tag is used much the same way a standard bean tag is used, except that instead of a class, the script-source attribute is assigned to the location of the actual Groovy source code.
Note, by the way, that the name script-source sounds like it implies that Groovy “scripts” are not compiled. That’s not true?—?the code will still be compiled after it’s loaded. Also, it sounds like it’s designed for a Groovy script, meaning code that isn’t inside a class. That isn’t necessary either. The script-source attribute here is assigned to a class called GroovyEvaluator.
The refresh-check-delay attribute represents the amount of time, in milliseconds, that the container waits before checking to see if the source has been changed. Here it’s set to one second.
What does the GroovyEvaluator class look like? Here it is:
Standard Groovy idioms apply here. For example, (1) the class is public by default, (2) the approve method is public by default, and (3) I don’t need a return keyword inside the approve method. Also, Groovy classes can implement Java interfaces without a problem.
Now, however, I have Spring bean configuration files in both Groovy and XML. One way to tie them together is to add an @ImportResource annotation to the Groovy configuration file:
AppConfig.groovy, modified to import the XML configuration file
@Configuration
@ComponentScan
@ImportResource("classpath:applicationContext.xml") // 1
class AppConfig {}
? Loads the beans in the XML file
(Still pretty Zen, but not as much. The lesson, as always: XML ruins everything.)
A regular @Import annotation is used to combine Java or Groovy configuration files. Here @ImportResource loads the applicationContext.xml file from the classpath and adds the bean definitions to the context. The nice part about using this approach is that you don’t have to change the client code (from the main method in JavaDemo) in any way.
Before proceeding, it’s probably a good idea to test the evaluators, though honestly there isn’t much in them by way of business logic. Still, it’s a good practice to test it anyway. Spring has great testing capabilities built in, involving its TestContext mechanism. Best of all, I can use the “Spock-Spring” dependency from the Gradle build file to write my test in Spock and still take advantage of Spring's dependency injection.
Here is a Spock test that checks the approve method in both the Java and Groovy evaluators.
EvaluatorSpec.groovy, a Spock test for the evaluators
@ContextConfiguration(classes = AppConfig)
class EvaluatorSpec extends Specification {
@Resource(name = 'javaEvaluator')
Evaluator javaEvaluator
@Resource(name = 'groovyEvaluator')
Evaluator groovyEvaluator
def 'dependency injection works'() {
expect: "injected references should not be null"
javaEvaluator
groovyEvaluator
}
def 'all Java mortgage applications are approved'() {
expect: javaEvaluator.approve(null)
}
def 'all Groovy mortgage applications are approved'() {
expect: groovyEvaluator.approve(null)
}
}
Normally I use the @Autowire annotation to bring my class being tested into the test itself, but since @Autowire actually uses “autowire by type” and both evaluators implement the same interface, I would have a conflict. I could resolve that with a @Qualifier annotation, but there's an easy alternative. The @Resource annotation from Java does “autowire by name”, so here I’m using it to bring in both of the evaluators individually.
The three Spock tests use an expect block. The Spock testing framework evaluates every statement in the expect block according to the Groovy truth (i.e., not null is true, non-zero is true, non-empty collections or strings are true, etc), and the test passes only if that condition is satisfied. In this case, the injected references are not null and both evaluators return true for any mortgage application, so we’re good, test-wise if not financially.
Returning now to the application, it’s time to demonstrate the refreshable bean. Here is a Groovy script (a real one this time) to do that, though I could have just as easily used Java for the same purpose:
groovy_demo.groovy, a script to run the refreshable bean
ApplicationContext ctx = new AnnotationConfigApplicationContext(AppConfig)
Evaluator evaluator = ctx.getBean("groovyEvaluator", Evaluator)
10.times {
boolean result = evaluator.approve(null)
println result ? 'approved' : 'denied'
sleep 1000
}
After loading the container and instantiating all the beans, the script finds the groovyEvaluator bean and casts it to type Evaluator. The times method on integer invokes its closure argument the integer number of times. In this case, it executes the approve method on the evaluator 10 times, sleeping for 1 second in between each. That gives me enough time to change the value in the source GroovyEvalutor source code to this:
GroovyEvaluator.groovy, updated to stop printing money
This change is made some time during the execution of the script.
I’ll show that in a moment, but before that there’s one last minor complication. As you may have noticed from the XML application context, the GroovyEvaluator.groovy file is not in src/main/groovy, it’s in src/main/resources. That’s because it doesn't need to be in the classpath, and I don’t want it to be in the classpath because I don't want it to be compiled. Instead, by putting it in the resources folder, I can still use it without compiling it. This does, however, confuse a poor IDE, which isn’t sure how to handle that situation at all.
(Btw, IntelliJ IDEA was confused for a while, but eventually figured it out.)
The easy work-around is to use Gradle to execute the script. That can be done by adding a custom task to the Gradle build file.
build.gradle task to execute the Groovy demo
task demo(type:JavaExec) {
main = 'com.kousenit.demo.groovy_demo'
classpath sourceSets.main.runtimeClasspath
}
The task is of type JavaExec, ironically enough, even though I'm calling a Groovy script. All I need to do is set the classpath to be the runtime classpath while executing the script, and everything runs properly.
If I run this by typing >gradle demo at the command line, the result is similar to:
There you have it. The GroovyEvaluator source code is deployed into the container, which checks every second to see whether or not it has been modified. When it is, Spring reloads and recompiles the bean and adds to the already running system. You don't even need to retrieve it again (note that the getBean method was invoked outside the loop). The changes are picked up automatically.
When Would You Actually Do This?
That’s all well and good, but most companies are understandably reluctant to deploy source code into production that can be changed while the system is running. So what good is this in practice?
Some problems simply aren't detectable unless the system is under significant load. Refreshable beans allow developers in a controlled environment to deploy what is effectively an intelligent probe into the system, which can be adjusted in any way needed. You might decide to log some other package, or process some data as it’s being collected, or, as here, change the actual behavior of a running system. The details are up to you.
(I'd link to the Spiderman movie here, but with all the reboots and bad sequels, I’ve pretty much given up on the franchise. So I’ll leave it to the late, great, Michael Conrad to have the final word: Let’s be careful out there.)
Ken Kousen is an independent consultant and trainer specializing in Spring, Hibernate, Groovy, and Grails. He is a regular speaker at conferences and the Author of "Modern Java Recipes" (O'Reilly Media), "Gradle Recipes for Android" (O'Reilly Media), and "Making Java Groovy" (Manning).